Overview
As the title suggests, this post presents a genuinely shocking result: recurrent neural networks can do far more than one would expect from such a simple formulation.
Training Over Programs
What makes recurrent networks exciting is not merely that they work on sequences, but how they work on them. Unlike vanilla neural networks that map fixed-size inputs to fixed-size outputs in a fixed number of computation steps, RNNs operate over sequences of vectors. It combines the current input with an internal state through a fixed (but learned) transition function, producing a new state at every step. The same transformation is applied repeatedly, allowing the model to naturally handle variable-length inputs, outputs, or both.
Training Recurrent nets is optimization over programs
This flexibility immediately enables a wide range of problem settings: sequence-to-one, one-to-sequence, and sequence-to-sequence mappings all fall out of the same framework. The model is no longer constrained by input size or output length, but instead by how long we choose to unroll it.
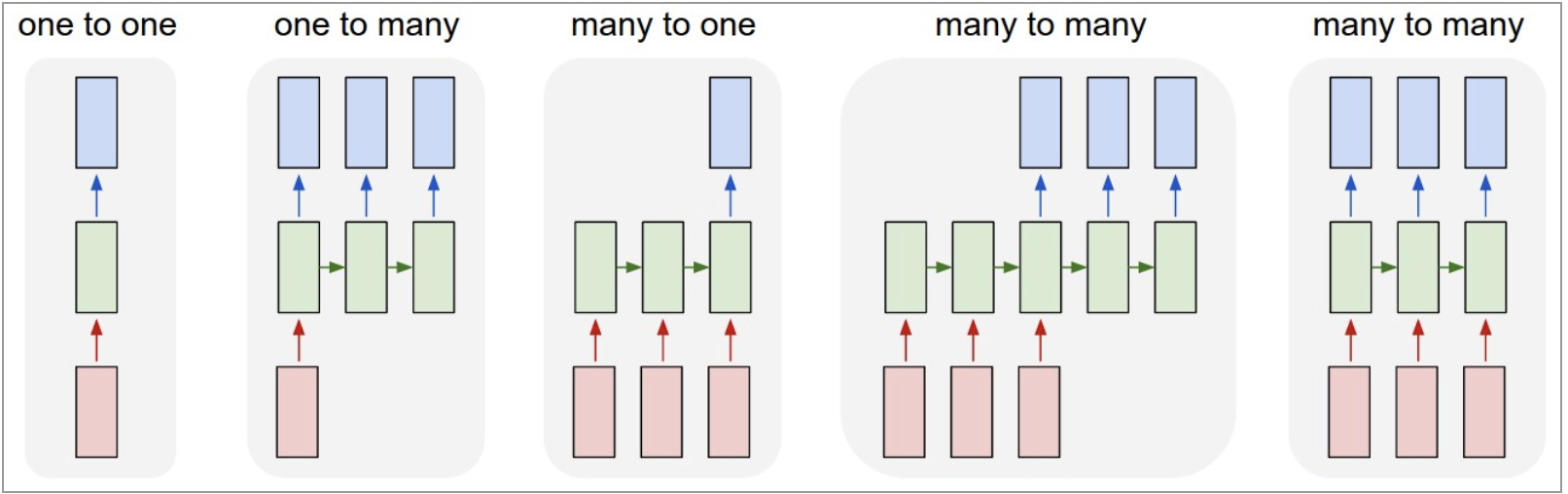
More interestingly, Karpathy points out that even when the input and output are fixed-size vectors, recurrent networks remain useful. By processing fixed data sequentially, RNNs effectively turn static inputs into a temporal process. In this view, the network is not learning a single transformation, but a stateful procedure—a small program that updates its internal state step by step.
This perspective reframes recurrent networks as something fundamentally different from feedforward models: rather than learning a static function, they learn how to operate over data through time.
Understanding Vanilla RNNs
A Recurrent Neural Network (RNN) is designed to handle sequential data by maintaining a “memory” of previous inputs.
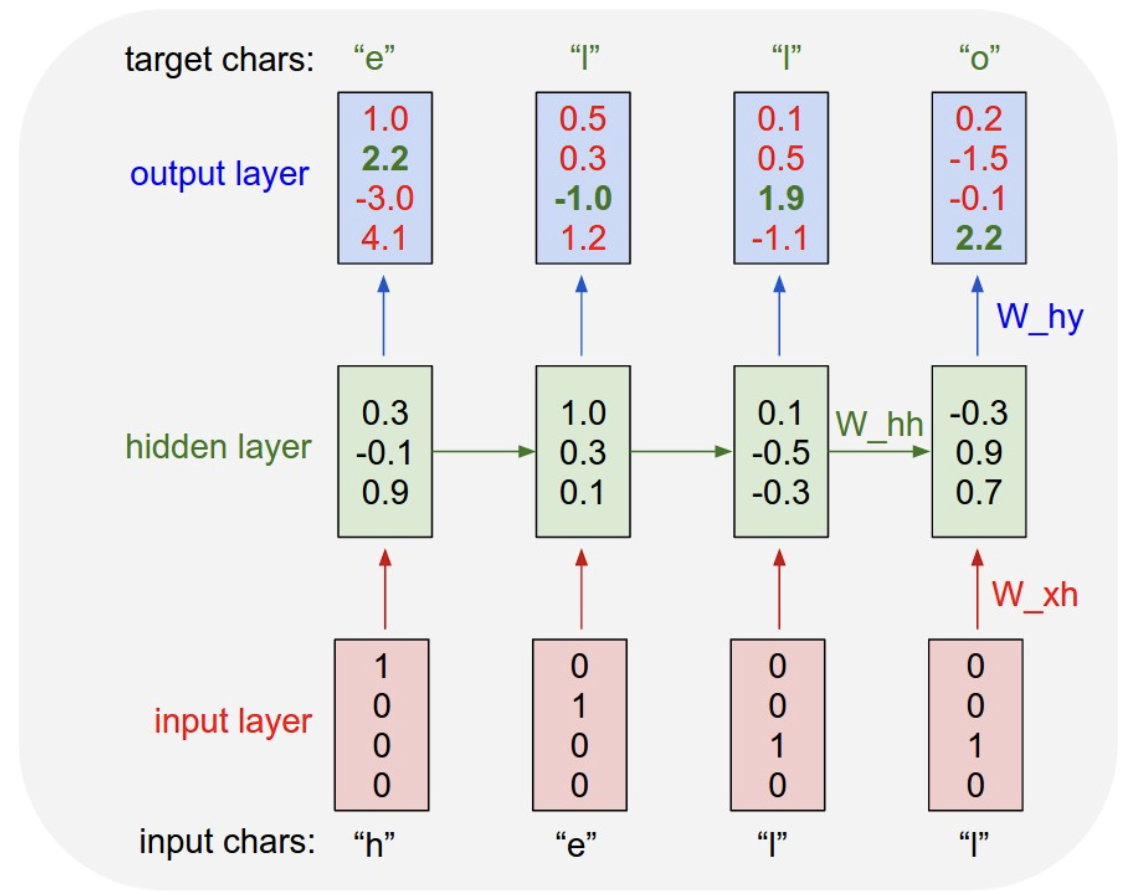
The Architecture Diagram
The diagram illustrates an RNN processing the sequence to predict the word “hello”:
- Input Characters: “h” “e” “l” “l”
- Target Characters: “e” “l” “l” “o”
- Input Layer: Uses one-hot encoding (e.g., ).
- Hidden Layer: A process where state is passed horizontally across time steps.
- Output Layer: Produces scores (logits) for the next character prediction.
The Linear Map
The Input-to Hidden Mapping
To move from the input layer to the hidden layer, we need a linear transformation. If we define:
- (The input vector)
- (The hidden state at time ) The operation follows the shape:
Therefore, the weight matrix exists in the space:
The Recurrent Step (Hidden-to-Hidden)
To maintain continuity, the previous hidden state is multiplied by the recurrent weight . if we define:
- Previous hidden state ():
- Recurrent weight (): Therefore:
The Hidden-to-Output Mapping
Finally, the current hidden state is mapped to the output space (e.g., for character prediction).
- Hidden state ():
- Output weight ():
We have:
While and often both equal the vocabulary size in character-level models, they are independent parameters. The Hidden Size, however, is a hyperparameter we choose to determine the capacity of the model’s memory.”
Why do we need ?
Notice that we need to move horizontally across the network. This is what makes a “Recurrent” Neural Network recurrent.
The “Why”: The network needs context to distinguish between identical inputs at different positions. For example, in the word “hello”:
- The first time the character “l” is input, the target is “l”.
- The second time the character “l” is input, the target is “o”.
Without the horizontal hidden state (), the network would have no way of knowing which “l” it is currently processing.
The RNN Mechanism
An RNN maps an input vector to an output vector . Crucially, the output values are influenced not only by the current input being fed, but the entire history of inputs processed so far.
Core Model Equations
For time t:
Input:
(one hot encoding).
Hidden State
The hidden state is updated using a activation function, which squashes the activations to the range :
In practice, we often have a bias vector.
Output:
Wrap up in softmax( cross-entropy loss)
In code:
class VanillaRNN:
# skip weight initializations.
def rnn_step(x_t, h_prev, params):
"""
Vanilla RNN forward pass
x_t: (input_size, 1)
h_prev: (hidden_size, 1)
"""
# update hidden state
h_t = np.tanh(np.dot(W_hh, h_prev) + np.dot(W_xh, x_t) + b_h)
# compute output:
y_t = np.dot(W_hy, h_t) + b_y
# Softmax
p_t = np.exp(y_t) / np.sum(np.exp(y_t))
return h_t, p_tA Note on Backpropagation Through Time (BPTT)
Loss Function and Backpropagation Through Time (BPTT)
Once the forward pass generates probabilities , we need to measure how well the model performed and update the weights.
Cross-Entropy Loss
For RNNs, the total loss is the sum of the losses at each time step. We use Cross-Entropy Loss, which penalizes the model based on the negative log-probability of the correct character.
The Gradient Flow: BPTT
Because weights () are shared across all time steps, we use Backpropagation Through Time (BPTT). We iterate backward from the last time step to the first, accumulating gradients.
A critical step in training RNNs is Gradient Clipping. Since we multiply gradients over many time steps, they can “explode.” Clipping forces the gradients to stay within a reasonable range (e.g., ).
def loss(ps, targets):
"""
ps: list of probability vectors for each time step
targets: list of ground-truth indices for each time step
"""
total_loss = 0
for t in range(len(targets)):
# -log of the probability assigned to the correct class
total_loss += -np.log(ps[t][targets[t], 0])
return total_loss
def backward(self, xs, hs, ps, targets):
"""
Backpropagation Through Time (BPTT)
xs: inputs, hs: hidden states, ps: probabilities
"""
dWxh, dWhh, dWhy = np.zeros_like(self.W_xh), np.zeros_like(self.W_hh), np.zeros_like(self.W_hy)
dbh, dby = np.zeros_like(self.bh), np.zeros_like(self.by)
# Gradient of the hidden state from the "future"
dhnext = np.zeros_like(hs[0])
# Iterate backwards through the sequence
for t in reversed(range(len(targets))):
# 1. Gradient of Loss w.r.t Output (dy = p_t - y_true)
dy = np.copy(ps[t])
dy[targets[t]] -= 1
# 2. Gradients for Output Layer
dWhy += np.dot(dy, hs[t].T)
dby += dy
# 3. Gradients for Hidden State (flowing back from output and next state)
dh = np.dot(self.W_hy.T, dy) + dhnext
# 4. Backprop through tanh: derivative is (1 - h^2)
dhraw = (1 - hs[t] * hs[t]) * dh
# 5. Accumulate gradients for weights and biases
dbh += dhraw
dWxh += np.dot(dhraw, xs[t].T)
dWhh += np.dot(dhraw, hs[t-1].T)
# 6. Pass the gradient to the previous time step
dhnext = np.dot(self.W_hh.T, dhraw)
# Gradient Clipping to prevent Exploding Gradients
for dparam in [dWxh, dWhh, dWhy, dbh, dby]:
np.clip(dparam, -5, 5, out=dparam)
return dWxh, dWhh, dWhy, dbh, dbyWhy this was a “wow” moment for me
What truly surprised me was not the RNN formulation itself, but the examples Karpathy showed.
By training on raw character sequences, the model could appear to understand highly structured domains such as mathematics and LaTeX. Of course, it does not actually understand proofs or mathematical meaning, but it can convincingly pretend to operate within those systems.
Seeing an RNN generate LaTeX that almost compiles, respects environments, and follows familiar mathematical notation was a turning point for me. It suggested that the usefulness of recurrent models goes far beyond natural language: any domain with strong syntactic regularities can be modeled as a sequence.
This was the moment I realized that the power of RNNs is not tied to semantics, but to structure. As long as a task can be expressed as a sequence of symbols with consistent constraints, a recurrent model can learn to behave as if it “understands” the domain—even when it clearly does not.
Reference:
https://karpathy.github.io/2015/05/21/rnn-effectiveness/ https://gist.github.com/karpathy/d4dee566867f8291f086 https://github.com/pageman/sutskever-30-implementations?tab=readme-ov-file