Introduction
An autoencoder is a neural network designed to learn a compressed, informative representation of input data. It does this by mapping the input x into a lower-dimensional latent code z (the latent space) using an encoder, and then mapping z back to a reconstruction using a decoder, with the goal that is as close as possible to x. A vanilla autoencoder is a deterministic latent-space model: for a fixed input x, the encoder always produces the same z, and no explicit probability distribution is involved.
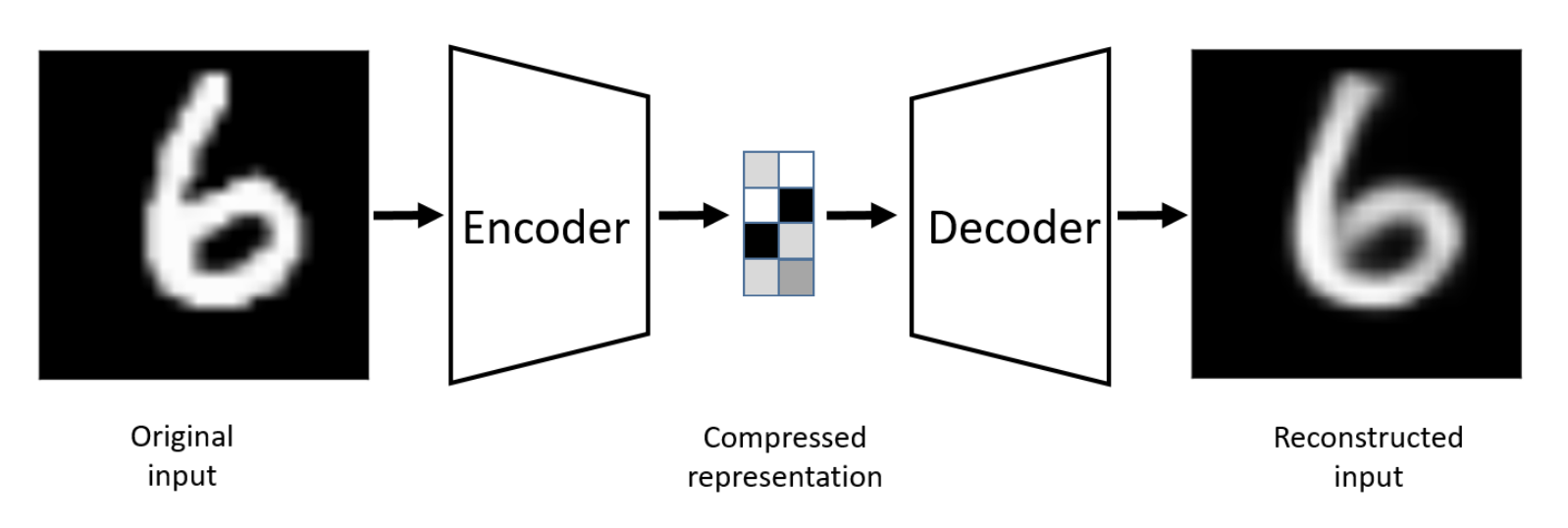
Note
Mathematically,
Let dataset where .
be a neural net with parameter , where it learns to encode x. be a neural net with parameter , where it learns to reconstruct x from its encoding.
The problem can then phrase to be
.
A autoencoder model use unsupervised learning to discover the latent variables of the input data(not directly observable but fundamentally inform the way data is distributed) then to reconstruct their own input data that has the same dimensions.
Types
-
Vanilla Autoencoders: Basic autoencoders that efficiently encode and decode data
-
Denoising Autoencoders: Improved robustness to noise and irrelevant information
-
Sparse Autoencoders: Learn more compact and efficient data representations
-
Contractive Autoencoders: Generate representations less sensitive to minor data variations
-
Variational Autoencoders: Generate new data points that resemble in some form the training data.
In essential, auto-encoders are designed to learn a lower-dimensional representation for a higher-dimensional data.
Applications include: 1. dimensionality reduction; 2. Feature extraction; 3. Image Denoising; 4. Image Compression; 5. Image Search; 6. Anomaly Detection; 7. Missing value imputation
Architecture:

The autoencoder maps the space of decoded message to the space of encoded message . In most cases, both and are Euclidean spaces( and for some )
We describe the autoencoder algorithm in two parts:
- encoder function: a parametrized family of encoder functions , parametrized by , that maps an input to a code
- decoder function: a parametrized family of encoder functions , parametrized by , that maps to
The decoder is designed to produce a reconstruction of the input .
Both the encoder and decoder function is defined as MLPs. A one-layer MLP encoder is in the form
- The Loss Function
The loss function penalizes for being dissimilar from X.
In the continuous setting, let be a reference probability distribution on X and be a distance function. Thus,
The optimal autoencoder is defined by the optimization problem
In practical, is empirical distribution given by a dataset
So is the Dirac measure
The distance function is typically chosen to be the square loss
Hence the optimal autoencoder search becomes:
Autoencoders are designed to be unable to learn the identity functions. It can learn useful properties of the data by prioritize which aspect of input should be copied.
Training
-
Number of nodes per layer : the standard autoencoder architecture we had above is called stacked autoencoder
-
Loss function : usual choices are MSE or crossentropy
-
Trained via backpropagation and mini-batch gradient descent
Interpretation:
An autoencoder is optimized to perform as close to perfect reconstruction as possible. In many applications, the goal is to create a reduced set of codings that represents the inputs.
An autoencoder whose internal representation has a smaller dimensionality than the input data is an undercomplete autoencoder.
Remark: When the autoencoder uses only linear activation functions and the loss function is MSE, then the autoencoder learns to span the same subspace as Principal Component Analysis (PCA)
When nonlinear activation functions are used, autoencoders provide nonlinear generalizations of PCA
Bottleneck is to prevent the autoencoder from overfitting to its training data. Otherwise, it tends toward learning the identity function
Thus:
Limitation:
-
when hidden code has the same dimension as input
-
Even in the case of an undercomplete autoencoder, the capacity of encoder/decoder is too high(processing large or complex data inputs)
-
Overcomplete case: hidden code has dimension greater than input
Regularization
By introducing regularization, we prevent autoencoder from learning the identity function.
-
Denoising Autoencoder
-
Sparse Autoencoder
-
Contractive Autoencoder
Denoisng autoencoder
Objective:
-
try to encode the inputs the preserve the essential signals;
-
try to undo the effects of a corruption process stochastically applied to the inputs of the autoencoder.
We train the autoencoder from a corrupted copy of the input.
corruption typically follows: additive Gaussian noise; masking noise; salt-and-pepper noise

DAE is associated to a different loss function as compared to a vanilla autoencoder
Loss function:
Letting the noise process be defined by a probability distribution over functions
Sparse Autoencoders
Objective
designed to pull out the*** most influential feature*** representations of the input data by using a sparsity constraint such that only a fraction of the nodes would have nonzero values.
A penalty directly proportional to the number of neurons activated is applied to the loss function
Sparse autoencoders may include more (rather than fewer) hidden units than inputs as the code is close to zero in most entries.
To enforce sparsity
- k-sparse
Suppose the encoder produces a latent vector:
-
Compute the absolute values: |x_1|, |x_2|, \dots, |x_n|.
-
Rank them from largest to smallest.
-
Keep only the top-k largest values (by magnitude).
-
Set all the other entries to zero.
Where if ranks in the top k, and 0 otherwise.
Backpropagating through : set gradient to for entries and keep gradient for entries.

The hidden nodes in bright yellow are activated.
- Add a sparsity regularization loss
Optimize for:
For each hidden layer k, we measure average activation:
-
: activation of neuron i in layer k given input x.
-
: average fraction of neurons active in that layer for input x.
We use a function to measure how far the actual sparsity is from the desired sparsity
Where
Choices for the function s: Kullback-leibler divergence; L1 loss; L2 loss
Contractive Audoencoder:
Adds a contractive regularization loss the the standard autoencoder loss that penalizes the network for changing the output in response to insufficiently large changes in the input.
The encoder is a function that maps input x to latent code z.
The Jacobian matrix of wrt x is:
Each entry shows how much a latent dimension changes when you nudge one input dimension.
If this Jacobian has small values → the latent code doesn’t change much when inputs vary slightly.
We measure the “size” of the Jacobian using the Frobenius norm:
The contractive regularization loss is:
They note that for small perturbations :
So:
-
If is small, then even if you perturb the input slightly (), the change in the code is small.
-
This makes the latent space stable and contractive around each data point.
Manifold Learning
Manifold Hypothesis
Data concentrates around a low-dimensional manifold
Some ML algorithm have unusual behavior if given an input that is off of the manifold.
Example:
Setting:
An image of size m \times n pixels can be written as a vector in , where
Let’s say A 100×100 image → .
So each image is one point in a huge-dimensional space.
Restriction:
Not All Pixel Combinations Make Sense
Most points in this huge space do not look like valid images of Einstein.
Valid Einstein images only occupy a very tiny subset of this space.
The manifold hypothesis says:
-
Even though Einstein images live in a high-dimensional space (N),
-
They actually lie on a low-dimensional manifold within it.
Definition of Manifold
An n-dimensional manifold is a topological space M for which every point has a neighborhood homeomorphic to Euclidean space .
Homeomorphism in topology is also called a continuous transformation
One-to-one correspondence in two geometric figures or topological spaces that is continuous in both directions
Homomorphism in algebra
The most important functions between two groups are those that preserve group operations, and they are called homomorphisms.
A function between two groups is a homomorphism when
A manifold has a dimension:
2-D manifold is a surface
1-D manifold is a curve
0-D manifold is a point
Manifold hypothesis = the decoder assumption of autoencoders/VAEs.
In the observed -dimensional input space, the data is distributed on an -dimensional manifold where
There exists a smooth function such that:
: hidden (intrinsic) coordinates on the manifold.
: the generative process that maps hidden factors into observed data.
the actual observed data point in high dimension.
tangent = local linear approximation of the manifold
At a point x on a d-dimensional manifold, the tangent plane is given by d basis vectors that span the local directions of variation allowed on the manifold
-
On a curve (1D manifold): the tangent line tells you the local direction of movement at a point.
-
On a surface (2D manifold): the tangent plane tells you the set of directions you can move infinitesimally while staying on the surface
Autoencoder performs trade-off between two forces
-
learns representation of training example x such that x can be recovered through a decoder
-
satisfies the regularization penalty
Together they force the hidden representation to capture information about the data generating distribution
The encoder learns to ignore noise (off-manifold directions) and focus only on meaningful changes (on-manifold tangent directions). That’s why autoencoders can capture the true low-dimensional structure of data.
https://cedar.buffalo.edu/~srihari/CSE676/14.3%20Learning%20Manifolds.pdf
Variational autoencoder
VAEs are trained to learn The probability distribution that models the input-data and not the function that maps the input and the output.
Difference between VAEs and other types of autoencoder:
VAEs learn continuous latent variable models
Most autoencoder learn discrete latent space models.
In a standard autoencoder, the encoder outputs a fixed latent vector:
This z is just a point in latent space (a deterministic code). There is no uncertainty — each input maps to one exact representation.
In a VAE, the encoder doesn’t output a point but a distribution over latent codes:
This makes z a continuous random variable sampled from a smooth space.
Objective
Given an input dataset x characterized by an unknown probability function and a multivariate latent encoding vector z, the objective is to model the data as a distribution with defined as the set of the network parameters so that
 VAE is generative AI models as it learns the latent distribution
VAE is generative AI models as it learns the latent distribution
VAEs can sample points from the latent distribution and feed them to the decoder to generate new samples that resemble the original training data
Application include: image generation and synthesis; Representation learning›

Loss function: two components:
-
The reconstruction loss: (MSE/ cross-entropy) Measures how different the reconstructed data are from the original data
-
KL-divergence: tries to regularize the process and keep the reconstructed data as diverse as possible.
Mathematical formulation
We want to model the data distribution , so we can:
-
Learn representations of data (encoding).
-
Generate new realistic samples (decoding).
Formally, we maximize the log-likelihood:
We introduce a latent variable that explains the data .
By the chain rule(factorization of a joint distribution ):
-
: prior (assumed to be .
-
: likelihood / decoder (how data is generated from latent ).
-
: posterior / encoder (how latent variables are distributed given data).
The posterior:
is usually intractable (the denominator requires integrating over all ).
Gaussian Assumption
Prior:
Decoder:
Where is a Gaussian distribution whose mean is defined by a deterministic function of the variable of z and covariance is a positive constant that multiplies
Encoder:
Approximate using variational inference
To set a parametrized family of distribution - for example the family of Gaussians, whose parameters are the mean and the covariance - and to look for the best approximation of our target distribution among this family.
This is found computationally by gradient descent over the parameters that describe the family.
We approximate the posterior with a variational distribution:
- is parameterized by the encoder neural network (mean + variance of a Gaussian).
to the parametrized families of functions G and H.
- The quality of approximation is measured by KL divergence:
Evidence Lower Bound (ELBO)
We derive a lower bound on :
Maximizing the ELBO
Is equivalent to simultaneously maximizing and minimizing
Rewrite:
Under the assumption that , that is, we model the distribution of x on z to be a Gaussian distribution centered on
Then:
Gaussian PDF:
>Take log:
>Assume unit variance ():
>Drop constants (they don’t affect optimization): >In VAE:, so:
We assume:
Encoder:
Prior:
And: The KL between two Gaussians has a closed form:
Thus:
Where is the dimension of z.
Reparameterization trick:
Problem: Directly sampling is random → no gradients can flow back to .
Trick: Write sampling as
Why it works:
Randomness comes only from (fixed distribution).
are differentiable → gradients can flow.
Result: Encoder and decoder can be trained end-to-end with backpropagation
VAEs Code Tutorial https://www.codecademy.com/article/variational-autoencoder-tutorial-vaes-explained
Step1 Setting up the VAE environment
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load MNIST dataset
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(
root="./data",
train=True,
transform=transform,
download=True,
)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=128,
shuffle=True,
)
Step 2 Building the VAE model architecture
(Encoder)
class Encoder(nn.Module):
def __init__(self, input_dim: int = 784, hidden_dim: int = 400, latent_dim: int = 20):
super().__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
(Decoder)
class Decoder(nn.Module):
def __init__(self, latent_dim: int = 20, hidden_dim: int = 400, output_dim: int = 784):
super().__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z: torch.Tensor) -> torch.Tensor:
h = torch.relu(self.fc1(z))
return torch.sigmoid(self.fc2(h))
Creating the main VAE class
class VAE(nn.Module):
def __init__(self, input_dim: int = 784, hidden_dim: int = 400, latent_dim: int = 20):
super().__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def reparameterize(self, mu: torch.Tensor, logvar: torch.Tensor) -> torch.Tensor:
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z: torch.Tensor) -> torch.Tensor:
return self.decoder(z)
def forward(self, x: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
mu, logvar = self.encoder(x)
z = self.reparameterize(mu, logvar)
recon_x = self.decoder(z)
return recon_x, mu, logvar
Here we used reparameterization tricks as sampling directly from a distribution breaks backpropogation. we sample ε ~ N(0,1) and compute z = μ + σ * ε instead.
Step 3 Defining the loss function
def loss_function(recon_x: torch.Tensor, x: torch.Tensor, mu: torch.Tensor, logvar: torch.Tensor) -> torch.Tensor:
# Reconstruction loss (binary cross entropy)
recon_loss = F.binary_cross_entropy(recon_x, x, reduction="sum")
# KL divergence loss
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return recon_loss + kl_loss
Step 4 Training the evaluating the VAE
epochs = 10
learning_rate = 1e-3
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
train_losses = []
model.train()
for epoch in range(epochs):
total_loss = 0.0
for batch_idx, (x, _) in enumerate(train_loader):
x = x.view(-1, 784).to(device) # Flatten images
optimizer.zero_grad()
recon_x, mu, logvar = model(x)
loss = loss_function(recon_x, x, mu, logvar)
loss.backward()
optimizer.step()
total_loss += float(loss.item())
avg_loss = total_loss / len(train_loader.dataset)
train_losses.append(avg_loss)
print(f"Epoch {epoch + 1}/{epochs} | Loss: {avg_loss:.4f}")
plt.plot(train_losses)
plt.title("VAE Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid(True)
plt.show()
Step 5: Testing the VAE by generating new samples
model.eval()
with torch.no_grad():
z = torch.randn(16, 20).to(device) # 16 samples, 20-d latent
generated = model.decode(z).cpu().view(-1, 1, 28, 28)
fig, axes = plt.subplots(2, 8, figsize=(12, 4))
for i, ax in enumerate(axes.flat):
ax.imshow(generated[i][0], cmap="gray")
ax.axis("off")
plt.suptitle("Generated Samples from Latent Space")
plt.show()
Step 6 Interpolating
def interpolate(model: VAE, z_start: torch.Tensor, z_end: torch.Tensor, steps: int = 10) -> torch.Tensor:
ts = torch.linspace(0, 1, steps, device=device).view(-1, 1)
vectors = z_start.to(device) * (1 - ts) + z_end.to(device) * ts # (steps, latent_dim)
model.eval()
with torch.no_grad():
samples = model.decode(vectors).cpu()
return samples.view(-1, 1, 28, 28)
z1 = torch.randn(1, 20)
z2 = torch.randn(1, 20)
interpolated_images = interpolate(model, z1, z2, steps=10)
fig, axes = plt.subplots(1, 10, figsize=(15, 2))
for i, ax in enumerate(axes.flat):
ax.imshow(interpolated_images[i][0], cmap="gray")
ax.axis("off")
plt.suptitle("Latent Space Interpolation")
plt.show()